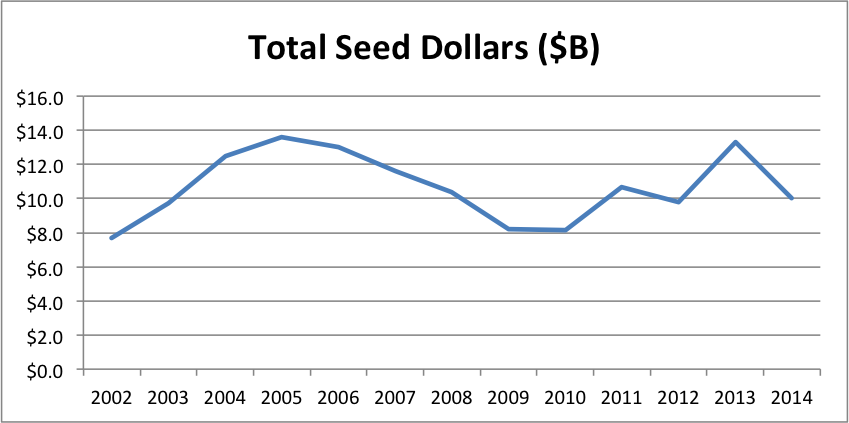
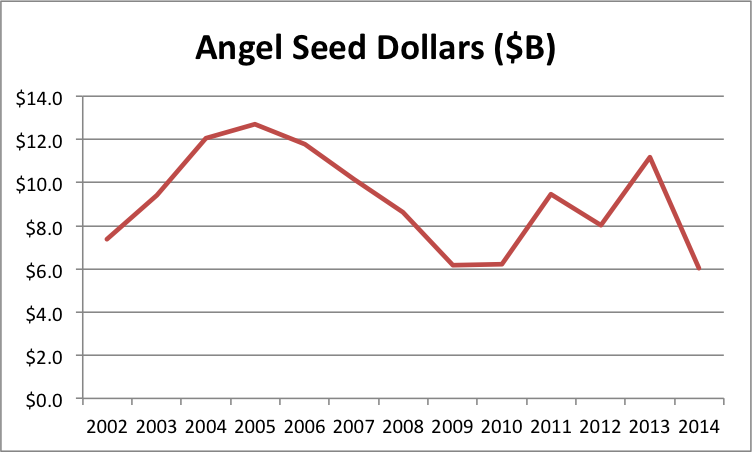
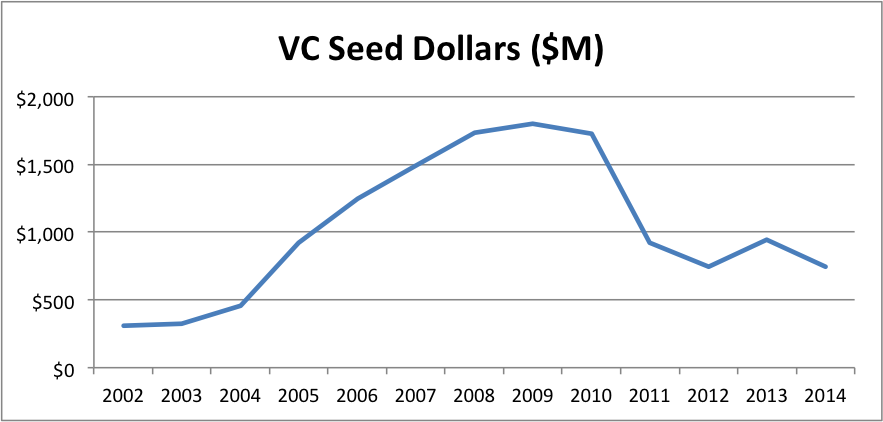
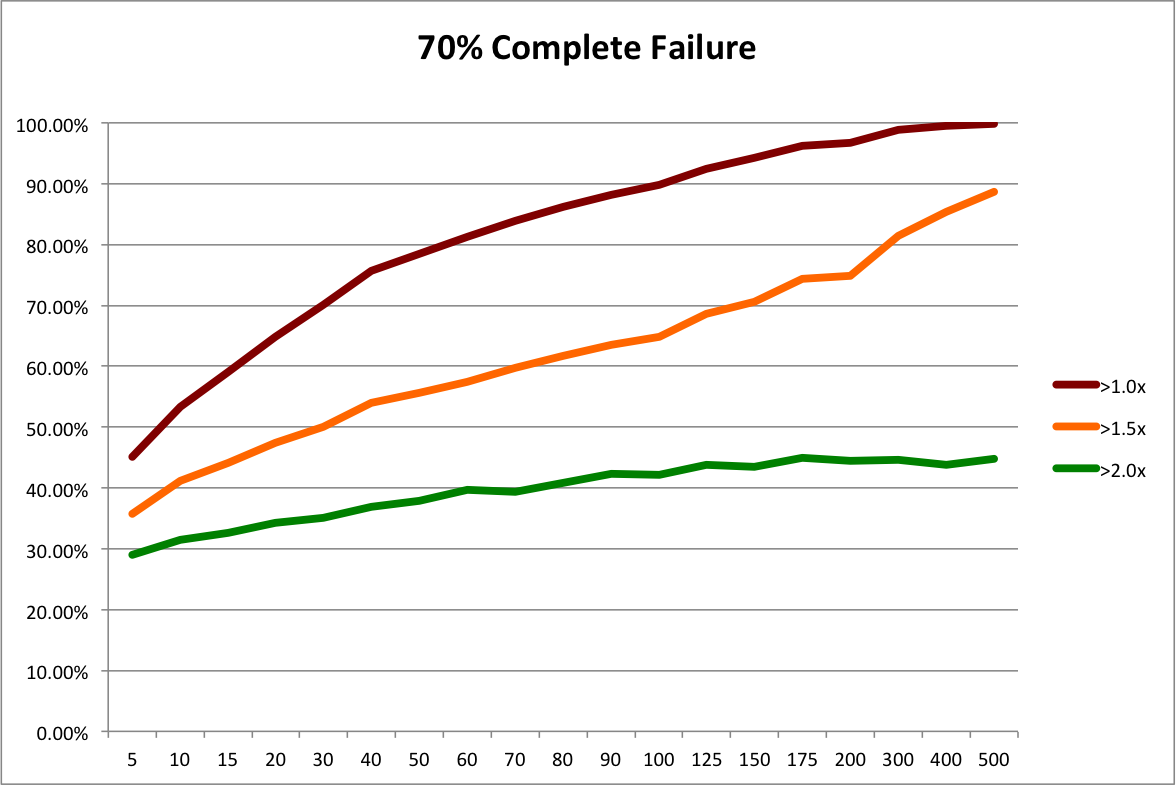
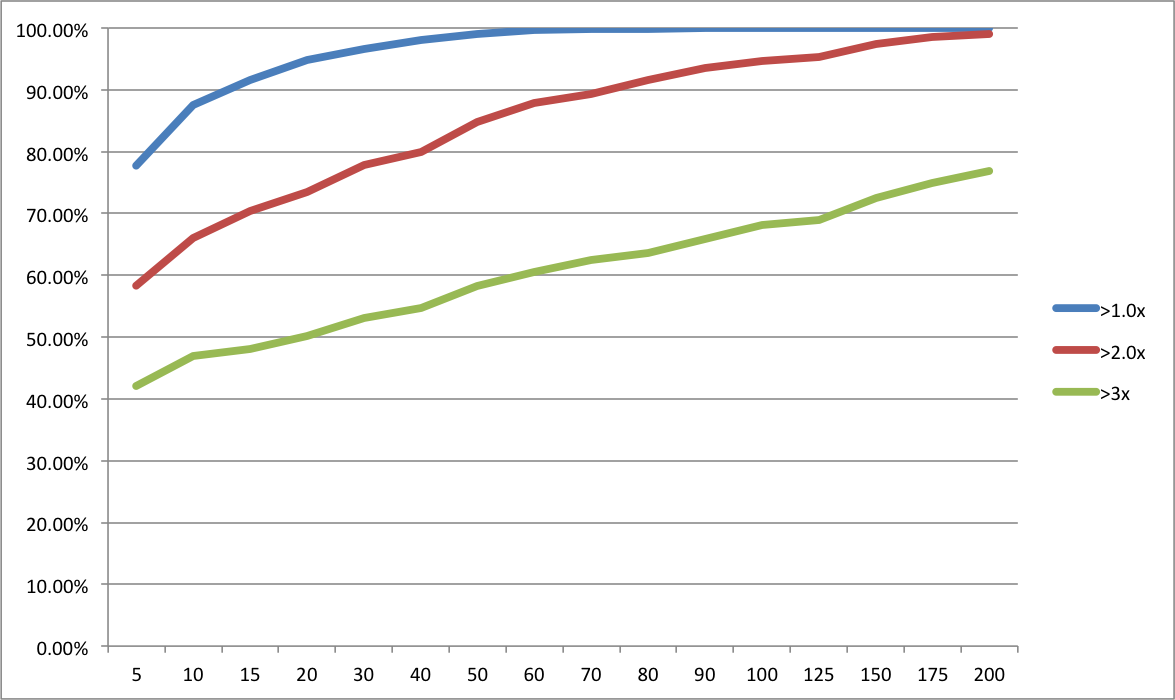
Regular readers know that I’ve been trying to bust the “Seed Bubble” myth for years. In my latest analysis, I show that total seed funding in 2014 was nearly identical to that in 2008, not even adjusting for inflation or economic growth. Over the last year, I’ve encountered several other persistent VC myths that similarly conflict with the data. Given that the seed bubble meme seems to be subsiding (though I dispute talk of a nonexistent bubble “popping”), I thought I’d tilt at some of these other windmills.
Myth 1: Series A Crunch
The easiest target is the myth of the “Series A Crunch”. As far as I can tell, the first mention of this hypothesis was in a November 2011 blog post by Elad Gil. After a year of bouncing around the echo chamber, this November 2012 Pando Daily article by Sarah Lacy was pretty typical: “Everyone — to a person — says it’s a real phenomenon…That means we’re getting a very different ‘nuclear winter’ as a result of industry excesses this time around.”
OK, so let’s look at the data on Early Stage VC dollars and deals from the NVCA. 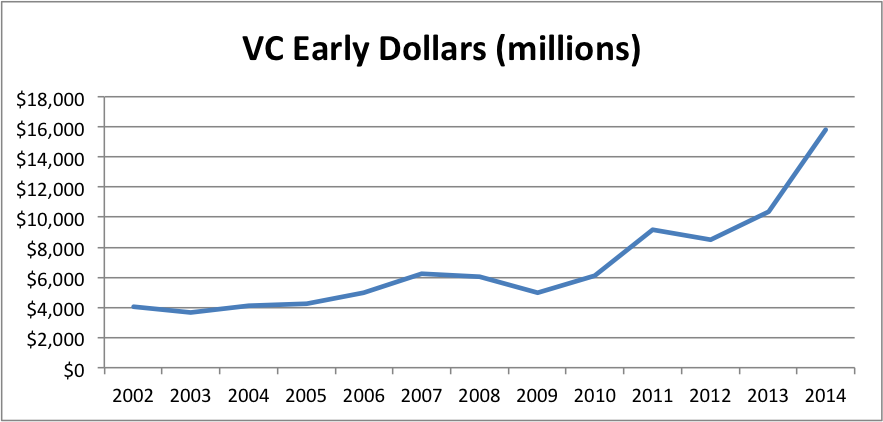
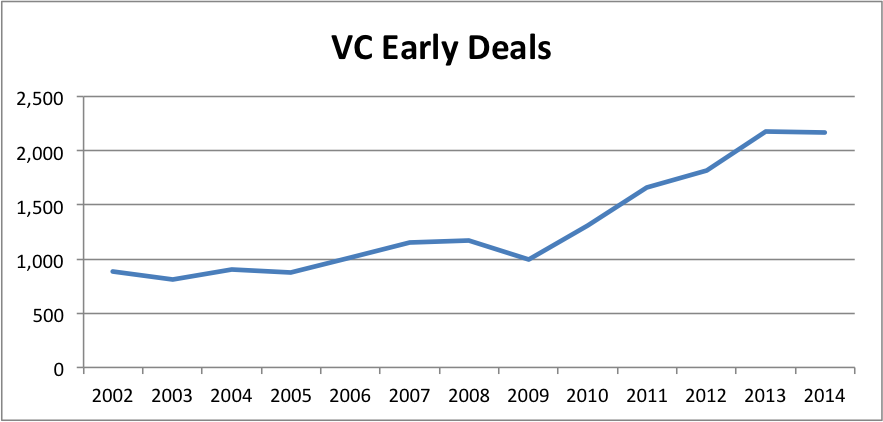
Hmm. I’m having trouble seeing much of a “crunch”. Pretty much up and to the right since 2009. Perhaps a slight valuation correction from 2011 to 2012, but deal volume was still going up. Certainly not a “nuclear winter”. Basic version of the myth.. busted.
Myth 2: Seed – Series A Imbalance
But there’s a variant of the Series A Crunch argument that the real problem is a Seed – Series A Imbalance. It’s not the absolute amount of Series A activity, rather there’s an overhang of increased Seed activity that is/will be causing a shortage of Series A down the line. Both the aforementioned Gil and Lacy pieces presage this twist. But this March 2015 Fortune article says it all in the title, “Free-flowing seed capital is giving startup founders a false sense of confidence,” and subtitle, “And it’s causing chaos ahead of the Series A round.”
Now, if you’ve read my Seed Bubble posts, you know that seed capital has not been “free flowing” over the past few years. But even I was shocked at the stark reality when I overlay VC Early and All Seed funding on the same graph.
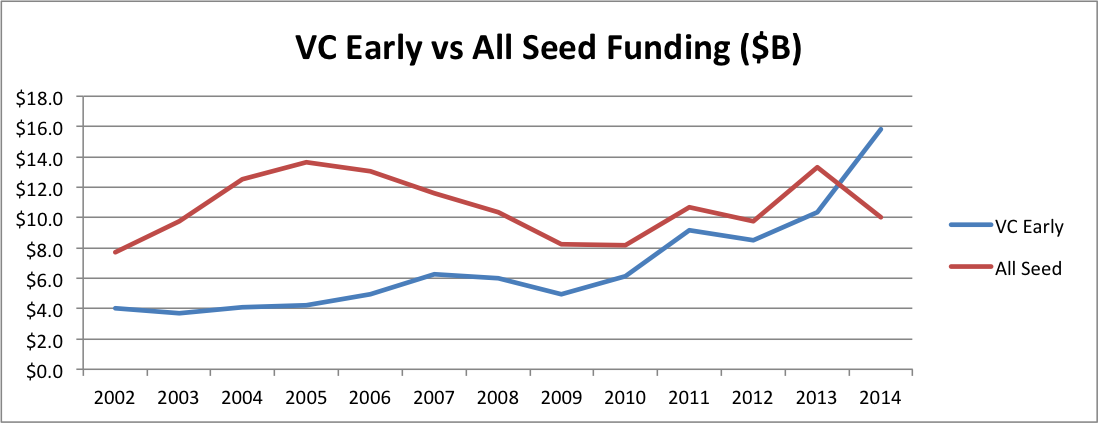
For a long time, seed funding was much greater than VC Early funding–twice the size or more. Then VC Early started to creep up. During the period of the supposed “Series A Crunch”, VC Early funding was actually shooting up from about 10% less to 60% more than All Seed. In fact, the ratio of VC Early to Seed tied the all time high in 2011 when the crunch supposedly began, then nearly doubled that record by 2014. If there’s an imbalance by historical standards, it’s the opposite direction!
Myth 3: “I’m Allocated to Seed”
Obviously, if people managing investment portfolios believe the Series A Crunch or Seed – Series A Imbalance myths, they won’t allocate dollars across startup stages correctly. This trap is compounded by a misimpression of the stages themselves. Many investors believe they are allocated to “seed” when in fact they have only fractional exposure to “something VCs call seed but is vastly different from the rest of the seed market.” From an allocation perspective, misidentifying your asset classes is a huge danger.
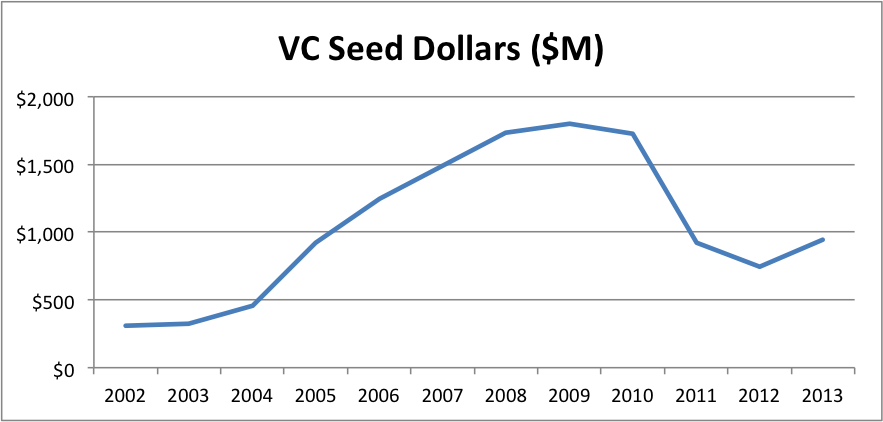
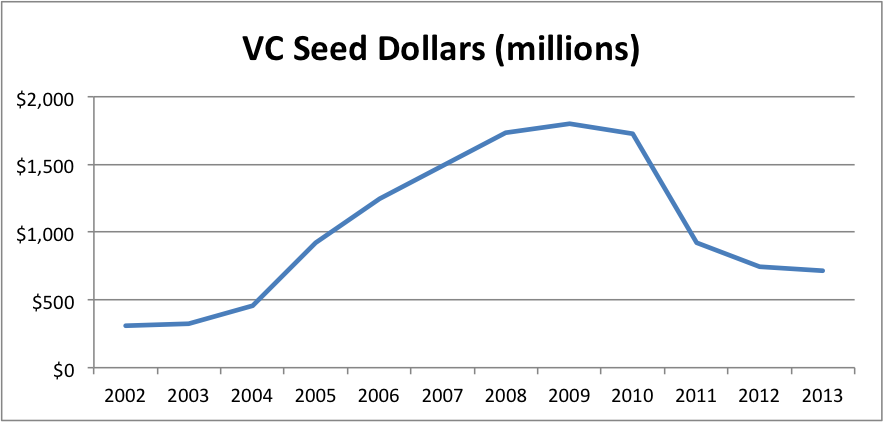
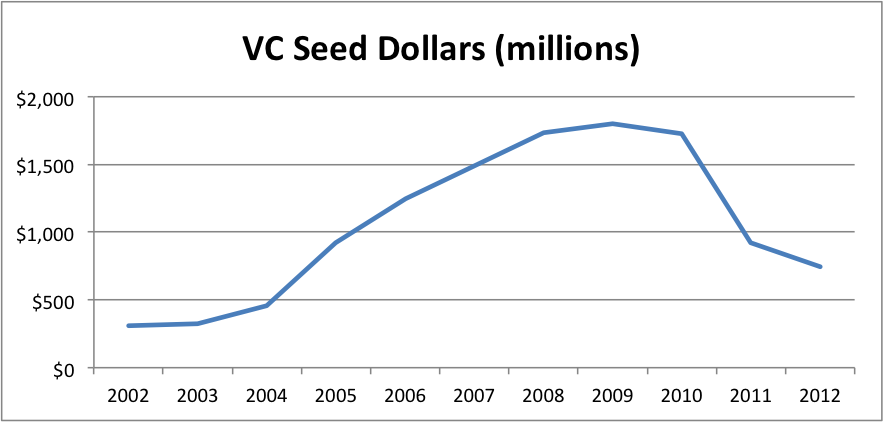
In my opinion, what VCs call seed is not the same as the rest of the market. Just look at the average size of a VC deal vs the average size of an angel deal. (Note that the angel number is the average size of at all stages so the graph actually understates the difference at the seed stage; unfortunately, CVR tracks angel deal volume, but not deal size, by stage.)
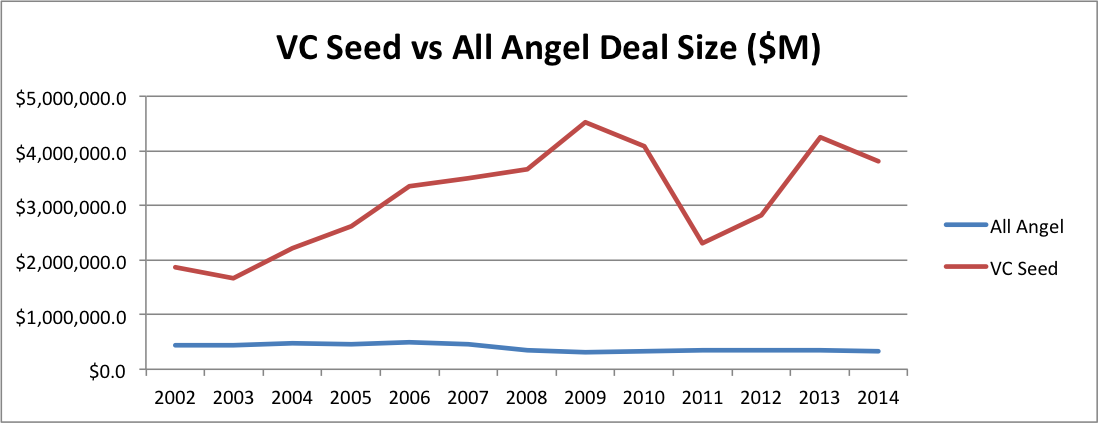
The ratio rose from about 4X in 2002 to 11.5X in 2014, with a peak of 14.5X in 2009. There’s clearly a categorical difference between what VCs and angels call seed.
Moreover, if you invest in an early stage VC fund, at best a modest fraction of each dollar actually goes to seed. Most early stage VCs make only a small subset of their initial investments at the round they call seed (unsurprisingly, most of the money goes into the round they call “early”). Moreover, even funds who always make their initial investments at what they call seed generally reserve at least $1 of follow-on for each initial $1. So at absolute best, investors who think they have seed exposure through VCs are getting half their dollars exposed to only the tiny slice of the seed market that accounts for the largest deals.
The share of this very high end of the market dropped precipitously in 2011.
In my opinion, the combination of all these factors means most investors in funds are dramatically under-allocated to over 90% of the seed stage technology startup market–a market that’s roughly the same size as the Early Stage VC market.
Does this difference matter? Well, if you’re worried about portfolio allocation to illiquid assets, you should be pretty concerned about the future liquidity options for such assets. From that perspective, here’s a sobering statistic from CB Insights (secondary source because primary requires registration):
In 2014, 73% of technology companies acquired never took traditional VC.
So if you believe that that VC Seed gets you exposure to the entire seed stage startup asset class, your portfolio will lack exposure to 3/4 of the liquidity options. By the way, this statistic is up from 2/3 in 2013. And with record amounts of cash on the large technology company balance sheets that make these acquisitions, I could easily see this bias growing further. Imagine a portfolio that lacks exposure to 80% or 90% of the liquidity events in that asset class! This third party data dovetails nicely with my previous calculation of a massive difference in the small M&A vs IPO and large M&A market.
I will stipulate that the VC-backed exits are almost certainly each bigger. But the goal of portfolio allocation is to balance out risks within and across asset classes. The data makes it clear that relying on VC Seed leaves a portfolio exposed to idiosyncratic risks within a particularly narrow exit market. So finding some way to target the other 90% of the seed stage technology startup market seems like prudent portfolio construction.
Of course, there may be different data out there or I may have botched the crunching somehow. So as always, feel free to check the work on my spreadsheet.