
As regular readers know, I’m a huge fan of the AIPP data set collected by Rob Wiltbank. In this TechCrunch article from a while back, Rob corrected the mistaken assertion that angels don’t make money. He also said that, “Angel investors probably should look to make at least a dozen investments…” While this statement isn’t wrong, neither is it as nuanced as I would like.
In this previous post, I used simulated data to examine the issue of adequate diversification. As it happens, I’ve also privately analyzed this issue using Rob’s AIPP data, an analysis I will now make public. [Hat tip to Paul P, a colleague with a professional financial statistics background who inspired and reviewed the original analysis, though any mistakes remain mine.]
To achieve my fully nuanced answer, I need to address two issues. But I’ll devote separate posts to each issue. This post addresses the issue that diversification is a tradeoff. More diversification will always protect you slightly more from idiosyncratic risk, all other things being equal (see my diversification posts one and two). But diversification isn’t free. It’s harder to make 10 investments than 1, and harder still to make 100. As an investor, you want to know how much each additional investment reduces idiosyncratic risk so you can make the right tradeoff for you.
To demonstrate this tradeoff, I’ll focus on RSCM‘s particular investing strategy: seed stage, no follow on, technology sector. I documented how I applied this strategy to the AIPP data set, complete with filtered data file, in this post. In principle, you could create a filtered data file for your own strategy as described in this other post and then apply the procedure below to calculate the precise diversification tradeoff for your strategy.
The key to the whole problem is a statistical technique called resampling; I’ll take the records from my filtered data file and create 10K portfolios for a variety of portfolio sizes, using random sampling with replacement. Then it’s straightforward to determine how much the historical returns at each portfolio size could vary. Essentially, we’re performing the following thought experiment: what if 10K angels randomly invested in the startups that Rob studied? What if they each invested in 10, 20, 30,… companies? How likely would a given angel have been to achieve a given return?
The return for the entire sample is a 42% IRR and a 3.7x payout multiple. The graph below shows the probability of achieving at least 1x, 2x, and 3x the original investment for a range of portfolio sizes. [Excel file with data, sampling macro, and probability macro is here.]
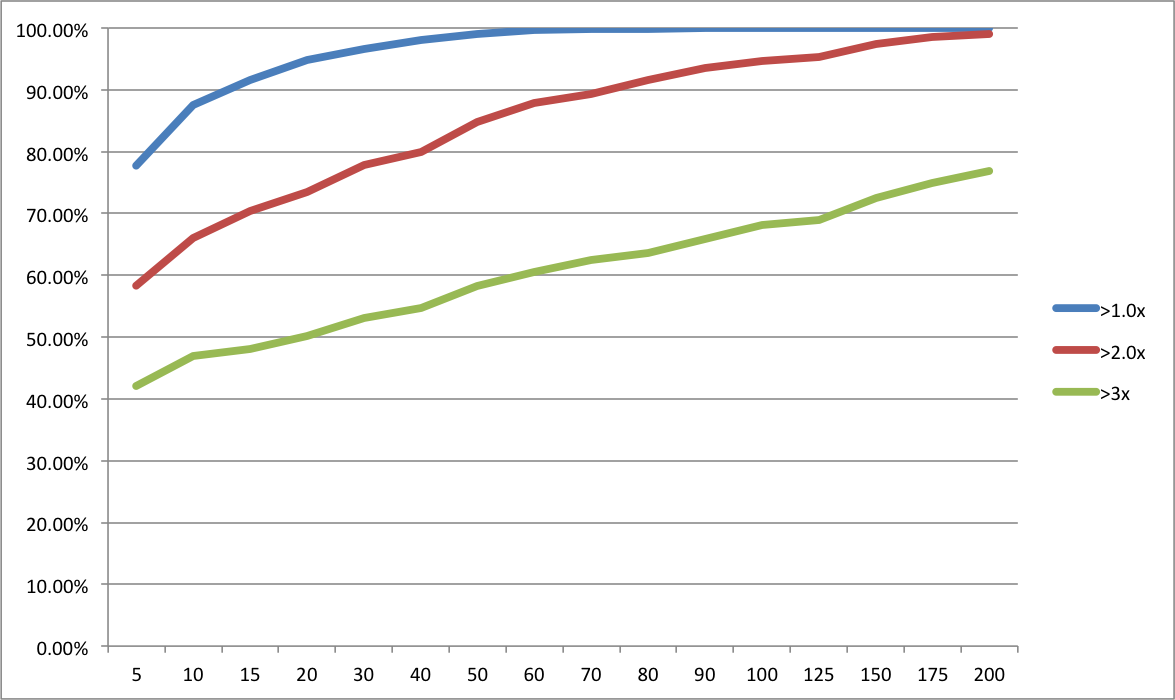
Now you can see the diversification tradeoff. Personally, I think a bare minimum is a 90% chance of getting at least your money back. That’s 15 investments based on the historical data. Roughly the same as Rob’s answer of a “dozen”. But I’d really prefer a 90% chance of doubling my money. That’s 70 investments. Now, if I’m managing other people’s money, I’d really like to push to an 80% chance of tripling their money, which is over 200 investments. I didn’t run 400 investments, but I’m guessing that is roughly the point at which you would have had a 90% chance of tripling other people’s money. [Update 4/2/2013: after doing a bunch or runs, it looks like it takes over 500 investments to achieve a 90% chance of tripling.] As far as I know, 500 Startups is the only firm other than RSCM that is even shooting for that level of diversification in a single portfolio.
So there’s my take on the first issue, diversification as a tradeoff. The second issue is essentially the old problem of, “Past performance is no guarantee of future results.” What if the return distribution of seed stage technology startups is different going forward than during the period Rob collected data? It turns out there’s a nifty way to use resampling to test the sensitivity of different levels of diversification to shifts in the return curve. That’s the topic of the next post.
[Updated 4/25/2013: corrected minor error in spreadsheet and graph]












